摘要
可行,但 Aida 的正确设计不是直接移植 Sirchmunk。
Sirchmunk 最有价值的想法不是“vector RAG”,而是查询时直接检索原始数据,并在成功搜索后保存可复用的
KnowledgeCluster。它的
AgenticSearch 先尝试复用已有 cluster,再回退到文件名 / 关键词 / 目录 / 证据抽取管线,最后把可复用
cluster、查询历史以及可选 embedding 持久化(/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:926,/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:1635,/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:1320)。这个模型对
Aida 很有参考价值。
Aida 应该把这件事实现成 Aida 自有、多租户、Postgres-backed 的
KnowledgeBase Module,并通过只读 internal tools 暴露给 Agent,而不是把它做成 Skill 文件,也不是引入
DuckDB/Parquet 本地缓存。在 Aida 中,Skill
明确是 prompt guidance,不参与工具可用性决策(CONTEXT.md:79,docs/adr/0010-progressive-tool-disclosure.md:21)。知识库搜索属于运行时数据访问,因此应该有独立的
Module、存储、Admin UI、审计和 Agent 工具面。
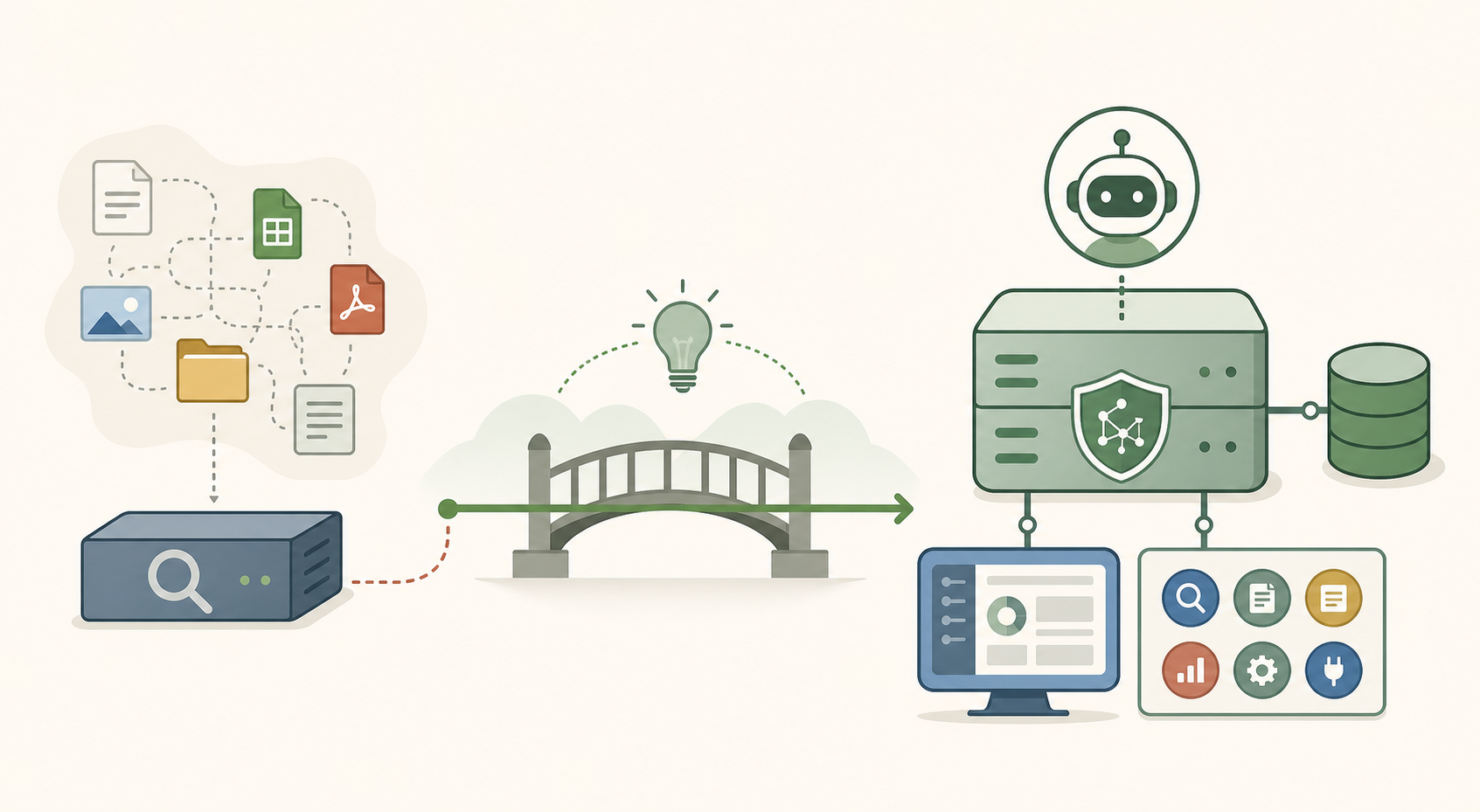
一眼看懂:借鉴思想,不搬运行时
左侧是 Sirchmunk 式本地文件搜索,中间是可借鉴的“搜索后沉淀知识”思想,右侧是 Aida 应该落地的多租户服务模块、Admin 管理、数据库和 Agent 工具面。
核心决策图
这张图概括本文最重要的取舍:借鉴 Sirchmunk 的知识复用模型,但把实现落在 Aida 自己的模块边界内。
推荐 MVP
- 在 Config DB 中增加由 Admin 管理的
KnowledgeBase、KnowledgeDocument、KnowledgeChunk、KnowledgeCluster表。 - 增加
/admin/knowledge-basesCRUD 和 Admin Web 中的KnowledgeBasesPage。 - 增加只读 internal tools:
searchKnowledgeBase、getKnowledgeCluster,可选listKnowledgeClusters。 - 用显式
knowledgeBaseIds把知识库绑定到 Agent 定义。 - 先支持 text / markdown / JSON / CSV ingestion 和 PostgreSQL full-text search;Phase 2 再加入 embedding 和更丰富的文档抽取。
Sirchmunk 实际实现
Sirchmunk 查询到沉淀流程
Sirchmunk 的关键价值在最后一步:成功搜索不是一次性答案,而是会沉淀成可复用的 KnowledgeCluster。
核心数据模型
Sirchmunk 的持久化单元是 KnowledgeCluster:一个被综合出来的知识单元,包含 name、description、content、evidence
list、confidence、lifecycle、query history、related clusters、source results,以及可选 semantic metadata(/Users/stanley/Repos/sirchmunk/src/sirchmunk/schema/knowledge.py:157)。Evidence
携带 doc_id、source path 或 URL、summary、snippet、extraction time,这正是 Aida 想要给出可信回答时需要的证据追溯能力(/Users/stanley/Repos/sirchmunk/src/sirchmunk/schema/knowledge.py:28)。
Cluster 在 retrieval 之后构建:Sirchmunk 从 top files 中抽取 evidence,调用 LLM synthesis,从合成文本派生确定性的 cluster
id,然后返回完整 KnowledgeCluster(/Users/stanley/Repos/sirchmunk/src/sirchmunk/learnings/knowledge_base.py:175,/Users/stanley/Repos/sirchmunk/src/sirchmunk/learnings/knowledge_base.py:280)。
存储
Sirchmunk 把 cluster 存在 in-memory DuckDB table 中,并周期性、进程退出时同步到 Parquet(/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:35,/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:205)。它提供
CRUD、fuzzy search、merge/split、stats、embedding persistence 和 cosine-similar cluster search(/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:472,/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:634,/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:958,/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:1045)。
这很适合 local-first 工具,但不适合 Aida 的 server Agent,因为 Aida 已经有 tenant-aware Postgres Config DB、audit
tables、Admin routes 和 request-scoped TenantContext。
搜索管线
Sirchmunk 有三个公开模式:FILENAME_ONLY、FAST、DEEP(/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:926)。FAST
先尝试 cluster reuse,然后做一次 LLM query-analysis、关键词搜索、聚焦证据采样、一次 LLM answer call,以及可选 cluster
persistence(/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:1608)。DEEP 会并行 probe:keyword extraction、directory scan、knowledge-cache
search、spec-cache load,然后进入 retrieval、evidence assembly、summary 或 ReAct refinement、persistence(/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:1106,/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:1153)。
它的 retrieval 基础是通过 ripgrep-all 做 indexless lexical search,并使用 shell=False
和结构化参数规避 shell 注入风险(/Users/stanley/Repos/sirchmunk/src/sirchmunk/retrieve/text_retriever.py:19)。它的
ReAct retrieval tools 包括 keyword search、file read、knowledge query,以及可选 directory scan(/Users/stanley/Repos/sirchmunk/src/sirchmunk/search.py:843)。
管理面
Sirchmunk 暴露了 REST endpoints,用于 knowledge refresh、list、get、search、stats(/Users/stanley/Repos/sirchmunk/src/sirchmunk/api/knowledge.py:14)。它的
MCP tool surface 包含 sirchmunk_search、sirchmunk_get_cluster、sirchmunk_list_clusters,这些
schema 可以比较自然地映射到 Agent tools(/Users/stanley/Repos/sirchmunk/src/sirchmunk_mcp/tools.py:21,/Users/stanley/Repos/sirchmunk/src/sirchmunk_mcp/tools.py:130,/Users/stanley/Repos/sirchmunk/src/sirchmunk_mcp/tools.py:153)。
当前 Aida 的适配度

三种路线的差异
现有杠杆点
Aida 已经有合适的接入点:
- Config DB DDL 集中在
runConfigDDL,并且已经有 agents、skills、conversations、messages、runs、scheduled tasks、observability、channel config 等一等表(packages/agent/src/config/ddl.ts:10,packages/agent/src/config/ddl.ts:30,packages/agent/src/config/ddl.ts:148,packages/agent/src/config/ddl.ts:328)。 - Admin Config routes 已经处理 CRUD、write auth、audit emission,并且承载 Providers、Skills、Agents、Entitlements、ScheduledTasks、Channels 等配置页面(
packages/agent/src/gateway/admin-config.ts:226,packages/agent/src/gateway/admin-config.ts:374,packages/agent/src/gateway/admin-config.ts:700)。 - Admin Web 已经有 API client 和复杂的 Skills 管理页面,可以复用其文件 / 文档树、编辑器、详情布局模式(
packages/web/src/lib/admin-api.ts:18,packages/web/src/pages/SkillsPage.tsx:71)。 - Runtime Agent preparation 已经有清晰的 pre-flight step,会按 resolved Agent 组装 tools 和 prompt(
packages/agent/src/gateway/prepare-agent-context.ts:46)。 - Internal read tools 已有模式:
readSkillFile和 scheduled task management 都在internal-tools.ts中构建,internal tools 会按 Run 与 domain tools 合并(packages/agent/src/orchestrator/internal-tools.ts:105,packages/agent/src/orchestrator/internal-tools.ts:312,packages/agent/src/orchestrator/agent.ts:127)。 TenantContext可以在 internal tools 内通过getTenantContext()取得,scheduled task tools 已经这样使用(packages/agent/src/orchestrator/internal-tools.ts:184)。
关键约束
Skill 当前是 prompt-content carrier:buildSkillContext 会 inline SKILL.md,并只列出
references/* 供按需读取(packages/agent/src/config/services/skill-service.ts:400)。ADR-0010 明确 Skill 不决定工具可用性,Agent.toolDomains
才决定工具域(docs/adr/0010-progressive-tool-disclosure.md:17,docs/adr/0010-progressive-tool-disclosure.md:21)。知识库搜索是 data access,不是 prompt guidance。
Aida 当前直接挂载 read tools,并通过 discoverTools 隐藏 write tools(docs/adr/0010-progressive-tool-disclosure.md:25)。searchKnowledgeBase
是只读工具,不需要确认流程。后续如果允许 Agent 触发用户驱动的文档 ingestion 或删除,这些必须是 write tools,并走
requestConfirmation。
Sirchmunk 的本地缓存面向单进程 local search 优化。Aida 需要 tenant isolation、Admin auth、auditability 和共享 runtime state。Postgres 已经是 Config DB 和 conversation persistence 的权威来源。引入第二套本地 durable store 会绕开 Aida 现有的 locality 和 safety 属性。
建议的 Aida 架构
Aida-native 知识库模块分层图
图中每一层都对应 Aida 已有的扩展点,避免把知识库做成另一个绕过权限、审计和租户隔离的旁路系统。
领域术语
实现开始时,建议把这些术语加入 CONTEXT.md:
- KnowledgeBase:租户作用域内、可被 Agents 搜索的语料集合。
- KnowledgeDocument:注册在某个 KnowledgeBase 内的文档或资源。
- KnowledgeChunk:从 KnowledgeDocument 中抽取出的可搜索文本片段。
- KnowledgeCluster:由成功搜索生成的、可复用的综合答案 / 证据包。
- KnowledgeSearch:只读 Agent 操作,返回 grounded snippets 或可复用 KnowledgeCluster。
存储模型
建议增加以下 Config DB tables:
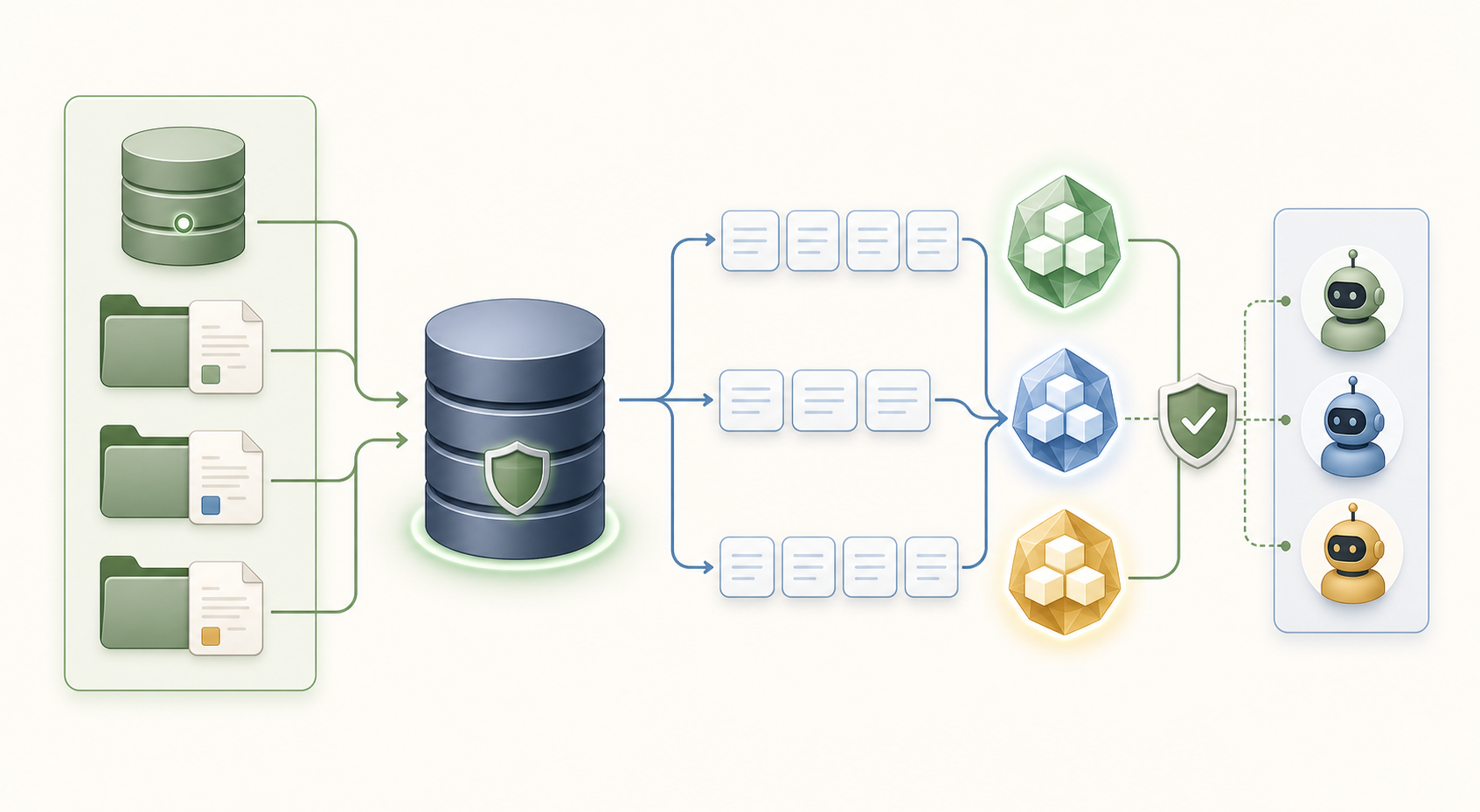
数据怎么流动
文档进入租户级 KnowledgeBase,被拆成可搜索 chunks;成功搜索会形成 reusable clusters;Agent 只有通过绑定关系和租户过滤,才能搜索对应知识库。
核心实体关系图
- tenant-scoped 语料集合
- Admin 管理生命周期
- 被 Agent 显式绑定
- 属于一个 KnowledgeBase
- 保存 title、source_type、source_uri
- 用 content_sha256 支持去重
- 属于 document 和 base
- 存储可搜索文本片段
- 生成 tsvector 做 full-text search
- 由成功搜索沉淀
- 保存 evidence、query_history
- 支持复用、hotness 和 lifecycle
- Agent 与 KnowledgeBase 的显式关系
- 决定工具是否挂载
- 便于反查与删除约束
- 所有查询按 tenant_id 过滤
- 防止跨租户读取
- 贯穿 Admin 和 runtime
关系主线是 KnowledgeBase → Document → Chunk;Cluster 是搜索成功后的可复用结果;AgentKnowledgeBase 决定某个 Agent 能否看到这组知识。
查看 DDL 草案
knowledge_bases (
id uuid primary key default gen_random_uuid(),
tenant_id text not null,
name text not null,
description text not null default '',
status text not null default 'active',
created_by text not null,
created_at timestamptz not null default now(),
updated_at timestamptz not null default now(),
unique (tenant_id, name)
);
knowledge_documents (
id uuid primary key default gen_random_uuid(),
knowledge_base_id uuid not null references knowledge_bases(id) on delete cascade,
tenant_id text not null,
title text not null,
source_type text not null,
source_uri text,
content_sha256 text not null,
status text not null default 'ready',
metadata jsonb not null default '{}',
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
knowledge_chunks (
id uuid primary key default gen_random_uuid(),
document_id uuid not null references knowledge_documents(id) on delete cascade,
knowledge_base_id uuid not null references knowledge_bases(id) on delete cascade,
tenant_id text not null,
chunk_index int not null,
content text not null,
tsv tsvector generated always as (to_tsvector('simple', content)) stored,
metadata jsonb not null default '{}'
);
knowledge_clusters (
id uuid primary key default gen_random_uuid(),
knowledge_base_id uuid not null references knowledge_bases(id) on delete cascade,
tenant_id text not null,
query_history text[] not null default '{}',
name text not null,
content text not null,
evidence jsonb not null default '[]',
confidence double precision,
hotness double precision,
lifecycle text not null default 'emerging',
created_at timestamptz not null default now(),
updated_at timestamptz not null default now()
);
agent_knowledge_bases (
agent_id uuid not null references agents(id) on delete cascade,
knowledge_base_id uuid not null references knowledge_bases(id) on delete cascade,
primary key (agent_id, knowledge_base_id)
);
建议使用 agent_knowledge_bases,而不是给 agents 再加一个 text-array 字段。这是一个真实关系,会让
Admin UI 反查、删除行为、租户过滤都比 skill_ids 更简单。
运行时接口
增加 KnowledgeService Module:
listAgentKnowledgeBases(agentId, tenantId)searchKnowledgeBase({ tenantId, agentId, query, knowledgeBaseIds?, limit? })getKnowledgeCluster({ tenantId, clusterId })recordClusterHit({ tenantId, clusterId, query })saveClusterFromSearch(...)
增加只读 internal tools:
searchKnowledgeBase:Input 为query,可选knowledgeBaseIds、limit、mode: "fast" | "deep";Output 是可直接用于回答的 evidence pack:matched chunks、document metadata、source ids、可选 reusable cluster。getKnowledgeCluster:Input 为clusterId;Output 是 cluster content + evidence。listKnowledgeClusters:可选,用于 Admin / Agent 自检,类似 Sirchmunk 的sirchmunk_list_clusters。
只在 resolved Agent 绑定了知识库时,才在 buildInternalToolSet 中挂载这些 tools。这与现有 readSkillFile
的条件注册方式一致(packages/agent/src/orchestrator/internal-tools.ts:321),也能保持工具 affordance 诚实。
Prompt 集成
不要把文档正文 inline 进 system prompt。
在 prepareAgentToolsAndPrompt 中,仅当 Agent 绑定了知识库时加入短 catalog segment:
查看 Prompt catalog 示例
## Knowledge Bases
You can search the following tenant-scoped knowledge bases with searchKnowledgeBase:
- HR Policies: internal HR policy documents
- Onboarding: onboarding guides and FAQs
这遵循现有 write-tool catalog 模式:prompt 中只放小目录,完整数据通过工具读取(packages/agent/src/gateway/prepare-agent-context.ts:82)。
搜索策略
Phase 1 应刻意保持简单:
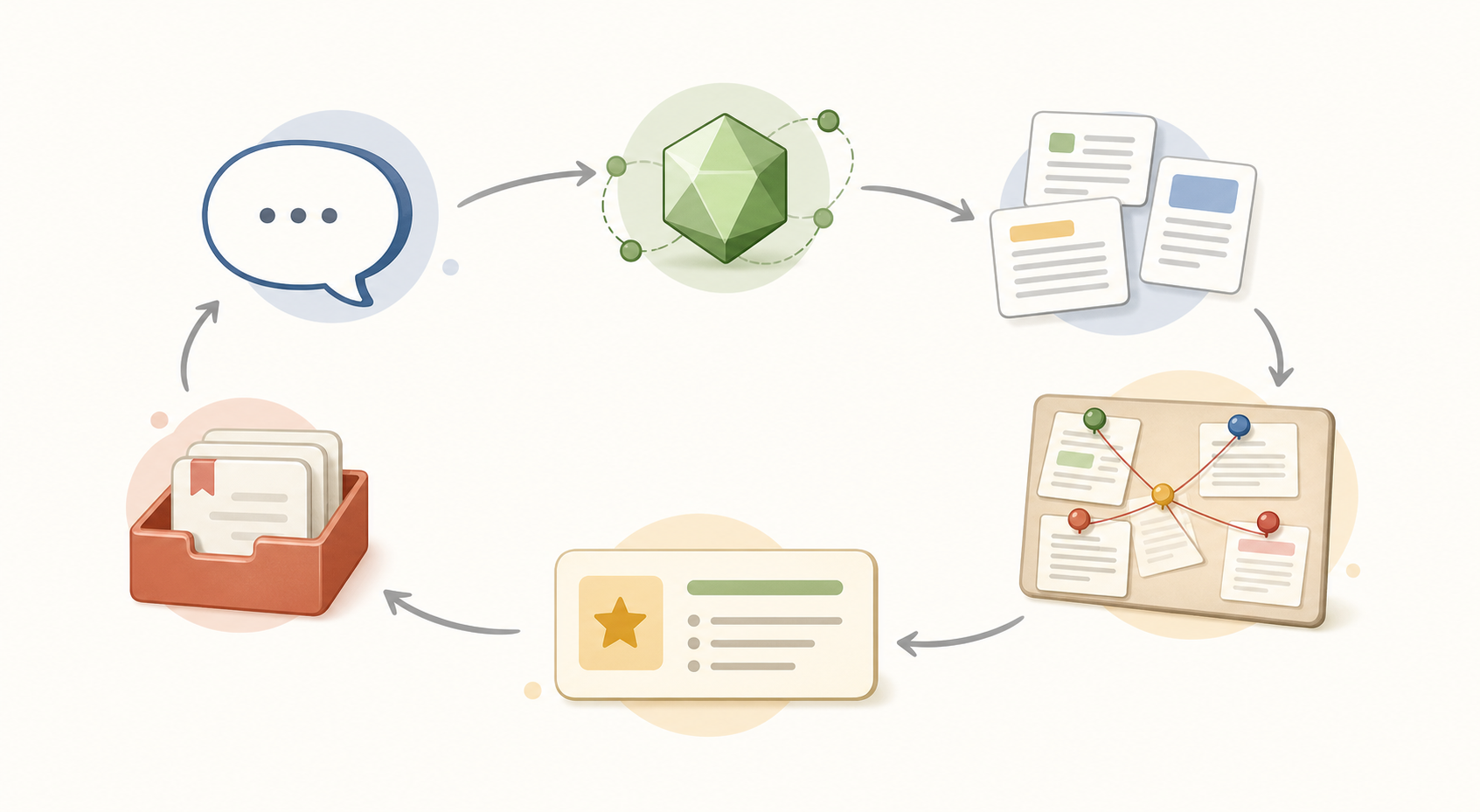
搜索不是一次性问答,而是可沉淀的循环
每次问题先尝试复用 cluster;如果没有命中,就检索 chunks、组装 evidence、生成回答;当证据足够强,再把结果沉淀回 cluster,下一次就更快。
Phase 1 搜索策略
MVP 搜索链路故意短:先做可解释的 lexical search 和 evidence pack,把 embeddings 与 DEEP refinement 留到后续阶段。
- Cluster reuse:先搜索
knowledge_clusters.query_history/name/content。 - Lexical retrieval:对
knowledge_chunks.tsv做 Postgres full-text search。 - Evidence pack:返回 top chunks,包含
documentId、title、score、snippets。 - 可选 LLM synthesis:可以让主 Orchestrator 直接使用 evidence,也可以让
searchKnowledgeBase合成 compact answer 和 evidence list。 - 只有证据足够强时才保存 cluster。
这能得到和 Sirchmunk FAST mode 类似的形状,同时不需要引入 subprocess、Python、DuckDB、Parquet、sentence-transformers 或
ripgrep-all。
Phase 2 可以加入 embeddings:
- 增加
embedding_model、embedding_vector、embedding_text_hash。 - 如果 Config DB Postgres 支持
pgvector,优先使用pgvector;否则保留 lexical search,并稍后增加外部 vector adapter。 - 从 query history 计算 cluster embedding,借鉴 Sirchmunk 的
combine_cluster_fields(queries)方法(/Users/stanley/Repos/sirchmunk/src/sirchmunk/storage/knowledge_storage.py:941)。
Phase 3 可以加入类似 Sirchmunk 的 DEEP mode:
- 基于 chat history 做 query rewriting。
- 并行进行 lexical + metadata + cluster reuse probes。
- 使用 LLM 做 evidence reranking。
- 自动创建带 confidence / hotness / lifecycle 的 cluster。
可行性评估
MVP 可行性:高
Admin CRUD、text ingestion、chunk storage、lexical search、只读 Agent tools 都与当前 Aida Modules 很匹配。整体主要是 additive change:
- DDL:
packages/agent/src/config/ddl.ts - Backend service:
packages/agent/src/config/services/knowledge-service.ts - Admin routes:
packages/agent/src/gateway/admin-config.ts - Runtime pre-flight:
packages/agent/src/gateway/prepare-agent-context.ts - Internal tools:
packages/agent/src/orchestrator/internal-tools.ts - Admin Web API/types:
packages/web/src/lib/admin-api.ts - Admin Web page:新增
KnowledgeBasesPage.tsx,复用SkillsPagepatterns
预计工作量:5-8 个工程日,可完成 text-only、Postgres full-text MVP,包含单测和小型 Admin UI。
生产级可行性:中高
更重的部分不是架构 blocker,但需要产品选择:
- PDF/DOCX/XLSX/PPTX 的 document extraction
- original files 的存储方式
- embedding provider 和 vector index 策略
- 谁可以读取或修改各个 KnowledgeBase 的 tenant/admin permission model
- search result quality evals
- observability 和 cost controls
预计工作量:3-5 周,可完成稳健 ingestion、更丰富文档格式、cluster reuse、eval coverage 和可用的 Admin UX。
直接移植 Sirchmunk 可行性:中低
把 Sirchmunk 直接嵌成 sidecar 可以很快做 demo,但对 Aida 风险较高:
- Python runtime 和
ripgrep-all不在当前 Node 20 / pnpm / ESM 技术栈里。 - DuckDB/Parquet 会在 Config DB 之外创建第二个 persistence authority。
- 本地文件系统
paths无法自然映射到多租户企业数据。 - tenant isolation 和 Backend Token 规则更容易被绕开;Aida-owned storage 更稳。
- Admin UI 和 audit 仍然要重建。
结论:把 Sirchmunk 当作设计参考,不要当作 runtime dependency。
实施计划
实施路线图
路线图从“正确的边界”开始,再逐步加入搜索质量和文档格式能力;这样能尽早形成可用闭环,也不牺牲后续演进空间。
-
Phase 0:决策与术语
把 KnowledgeBase 相关术语加入CONTEXT.md;决定 MVP 文档存储是 Postgres text-only,还是 local filesystem + metadata;决定 Agent 绑定是仅 per-Agent,还是 tenant entitlement 也控制 KnowledgeBase 可见性。 -
Phase 1:Admin-Managed Text KnowledgeBase
增加 DDL tables、knowledge-service.ts、/admin/knowledge-basesroutes,以及 Admin Web page;先支持.txt、.md、.json、.csv、.yaml;测试 service CRUD、tenant isolation、search ranking smoke tests、route auth。 -
Phase 2:Agent Runtime Search
在 Agent Admin UI 中增加agent_knowledge_bases编辑能力;扩展ResolvedAgentContext;把KnowledgeService加到 runtime deps 或ConfigFacade;条件注册searchKnowledgeBase/getKnowledgeCluster;增加 prompt catalog segment;测试 conditional tool exposure、tenant filtering、Orchestrator tool-call smoke test。 -
Phase 3:KnowledgeCluster Reuse
增加 cluster save/reuse 路径;实现 hotness / query-history updates;增加listKnowledgeClusters的 Admin 和 Agent 只读 surface;只有返回 evidence 至少包含一个 chunk,且 confidence 超过阈值时才保存;测试 cluster reuse hit、stale/deleted source exclusion、evidence traceability。 -
Phase 4:Rich Extraction And Embeddings
增加 PDF/DOCX/XLSX/PPTX extraction adapters;增加可选 embeddings,以及 hybrid lexical + vector retrieval;如果 ingestion/search 变成长任务,增加 streaming progress events;增加 Eval Charters,覆盖 groundedness、source citation、tenant isolation、missing evidence 时拒答。
风险与缓解
风险控制图
风险最高的不是搜索算法,而是边界、租户隔离和证据质量;这些都应在 MVP 就进入测试与设计约束。
| Risk | Impact | Mitigation |
|---|---|---|
| 把 KnowledgeBase 当作 Skill | High | 保持独立 schema 和 tools;Skill 按 ADR-0010 继续只做 prompt guidance。 |
| Search tool 返回内容过多 | Medium | 返回 compact evidence packs;限制 chunks 和 characters;沿用现有 context compaction discipline。 |
| 租户数据泄漏 | High | 每张表携带 tenant_id;每次查询按 TenantContext.tenantId 过滤;补 cross-tenant denial tests。 |
| 证据质量差导致幻觉回答 | High | 返回 source ids/snippets;保存 cluster 前加 quality gate;用 eval 验证 groundedness。 |
| 文档解析范围膨胀 | Medium | MVP text-only;后续用 adapter interface 承接 rich formats。 |
| Embedding 基础设施不确定 | Medium | 从 lexical search 起步;embedding 字段设计为 optional。 |
| 工具面膨胀 | Low | 只有 Agent 绑定了知识库时才条件注册 read tools。 |
推荐结论
构建 Aida-native MVP。
不要移植 Sirchmunk 的 Python/DuckDB/Parquet runtime。应该借鉴这些思想:
KnowledgeCluster 作为可复用结果单元 query history + hotness source-linked snippets FAST-first search cluster list/get/search/stats endpoints
第一个有价值的里程碑是:Admin 可以创建 text KnowledgeBase,把它绑定到 Agent;Agent 可以通过调用
searchKnowledgeBase,基于带来源证据的结果回答问题。这会形成正确的 Module depth,并为 Sirchmunk 式
self-evolving clusters 留出空间,同时不扭曲 Aida 现有架构。